
Feature Reduction Techniques
2017-07-13 MacLearn machine-learning feature-selectionA Mind Map of both Supervised and Unsupervised Feature Reduction Techniques
Retionale for Feature Reduction
- Mitigating the effect of curse-of-dimensionality and the risk of overfitting by preselecting the most relevant features and effectively discarding redundant features plus noise.
- Facilitating a deeper understanding of the scientific question of interest by selecting the features with most contributions to classification or regression.
- Saving the computation time by training the model with a dimension-reduced dataset.
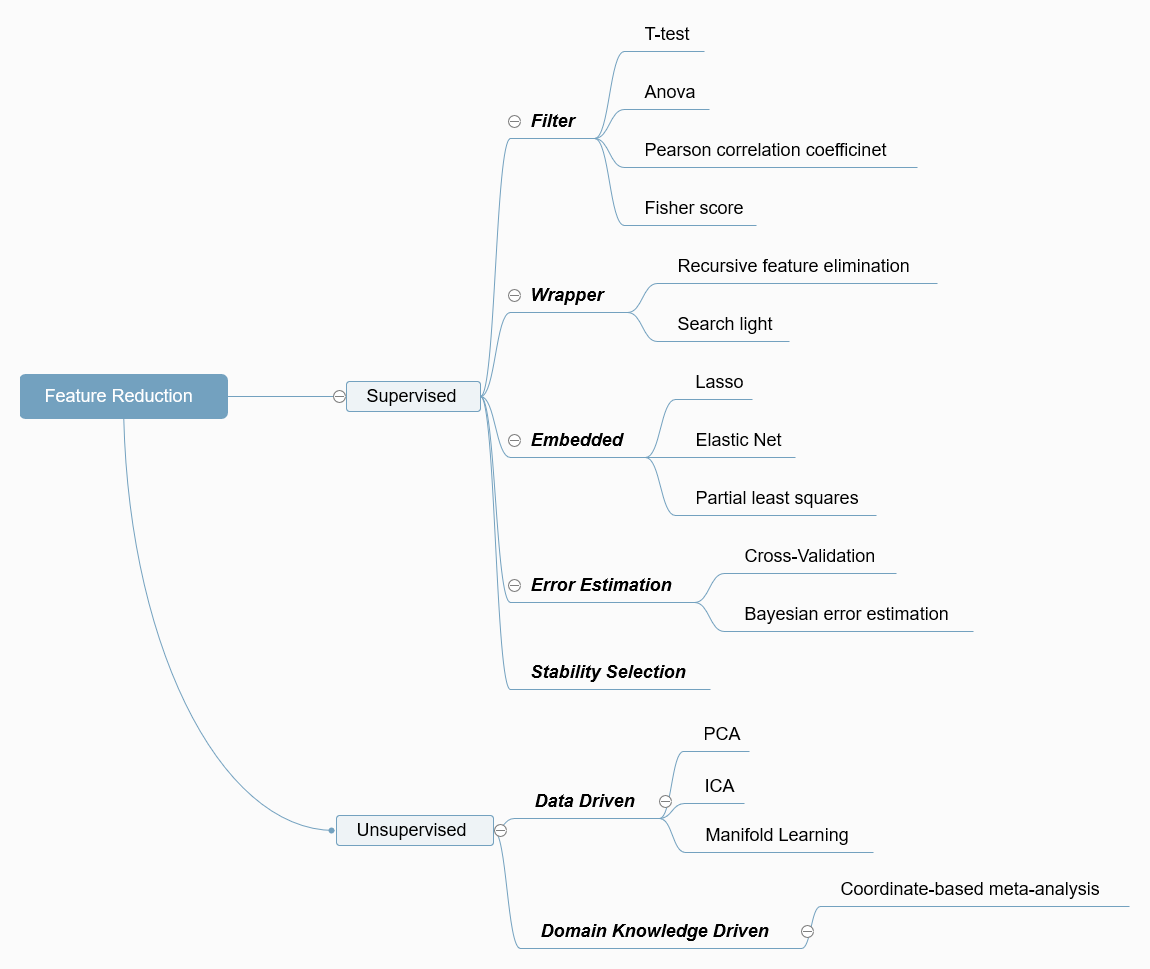
Brief Intro of Feature Reduction (Supervised) Methods
- Filters for feature selection
Filters use simple statistical measures (e.g. mean, variance, correlation coefficients) to rank features according to their relevance in detecting group-level differences. - Wrappers for feature selection
Wrappers use an objective function from a classification or regression machine learning model to rank features according to their relevance to the model. - Embedded feature selection
Embedded methods select relevant features as ‘part’ of the machine learning process by enforcing certain ‘penalties’ on a machine learning model thus yielding a small subset of relevant features. - Parameter selection based on error estimation
Selecting the regularization parameters based on error estimation. The parameter or feature combination giving the highest average accuracy (or AUC, recall-score, f1-score, etc.) is selected. Except for the non-parametric error estimation techniques (such as CV or bootstrap), the recently proposed alternative - “The Parametric Bayesian error estimator” can be applied to feature selection [1]. - Stability selection
Stability selection is a recently proposed approach by Meinshausen and Buhlmann [2] for addressing the problem of selecting the proper amount of regularization in embedded FS algorithms. This approach is based on subsampling combined with the FS algorithm. The key idea of this method is that, instead of finding the best value of the regularization and using it, one applies a FS method many times to random subsamples of the data for different value of the regularization parameters and selects those variables that were most frequently selected on the resulting subsamples.
Brief Intro of Feature Reduction (Unsupervised) Methods
- PCA
PCA is used to decompose a multivariate dataset in a set of successive orthogonal components that explain a maximum amount of the variance. - ICA
Independent component analysis separates a multivariate signal into additive subcomponents that are maximally independent. - Manifold Learning
Manifold learning is an approach to non-linear dimensionality reduction. Algorithms for this task are based on the idea that the dimensionality of many data sets is only artificially high. - Domain Knowledge Driven
Domain knowledge is valid knowledge used to refer to an area of human endeavour, an autonomous computer activity, or other specialized discipline. [3-4]
More about Dimension Reduction - [8]
Feature selection techniques in Scikit-Learn (0.17.1) [link]
- Filters
- Anova F-value
- Chi-squared stats
- F-score
- Tree-based Feature Selection
- The importance of a feature is computed as the (normalized) total reduction of the criterion brought by that feature. It is also known as the Gini importance [5].
- Wrappers for feature selection
- Embedded feature selection
- Stability selection
Dimension Reduction techniques in Scikit-Learn (0.18.2) [Link]
- Data Driven
Reference
[1] Dalton, L.A., & Dougherty, E.R. (2011). Bayesian minimum meansquare error estimation for classification error—part II: The Bayesian MMSE error estimator for linear classification of Gaussian distributions. IEEE Trans Signal Process
[2] Meinshausen and Buhlmann. (2010). Stability selection. Journal of the Royal Statistical Society: Series B (Statistical Methodology)
[3] Domain knowledge | Wikipedia
[4] Domain driven data mining | Wikipedia
[5] L. Breiman, and A. Cutler. Random Forests. [Home]
[6] Benson Mwangi & Tian Siva Tian & Jair C. Soares. (2013). A Review of Feature Reduction Techniques in Neuroimaging. Neuroinform
[7] J Tohka, E Moradi, H Huttunen. (2016). Comparison of Feature Selection Techniques in Machine Learning for Anatomical Brain MRI in Dementia. Neuroinform
[8] L.J.P. van der Maaten, E.O. Postma, H.J. van den Herik. (2008). Dimensionality Reduction: A Comparative Review Preprint
Comments