
特征选择的现实意义
2017-06-15 MacLearn machine-learning feature-selection特征选择在很多方面都非常有用:它是对抗维数灾难的最好武器;它能减少训练时间;它还是减轻过拟合、提高泛化性能的有利手段。 By Matthew Mayo, KDnuggets
比如你想对动物进行分类,基于一个过剩的数据集,你会很快发现各种可能的数据属性(特征)对分类都没什么用。例如所有活的生物都有且只有一个心脏,这个特征从学习的角度来说是没有用的。从另一方面讲,一个指明当前动物是否有蹄子的特征会是一个很好的预测量变量(predictor)。
进一步讲,将不相关的特征和非常有效的预测变量混合会对预测模型造城非常不好的影响。也就是说,加入无关特征会增加训练时间,并可能导致在训练数据集的过拟合。
特征选择是缩小特征子集的过程,通常用于预测建模。特征选择在很多方面都非常有用:它是对抗维数灾难的最好武器;它能减少训练时间;他还是减轻过拟合、提高泛化性能的有利手段。
我最近读到的数据科学家Rubens Zimbres的文章 – written so eloquently and concisely – 从现实角度提及了特征选择的重要性:
经过实践,使用层叠神经网络,平行神经网络,不对称配置,简单神经网络,multiple layers,dropouts,activation functions等等技术得到一个结论:都不如特征选择好使。
我曾经与Rubens Zimbres进行过专业交流,我请求他传授些技巧,他的分享如下:
特征选择应该成为一个数据科学家主要的关注点之一。特征选择能够提高正确率和泛化性能,藉由相关性、偏度(skewness)、t-test、ANOVA、熵、信息增益等。
许多时候正确的特征选择能使你训练出更加简单更加快速的机器学习模型。请看下面的图片(SVM对IRIS数据集分类): 左侧代表错误的变量选择,右侧袋面正确的变量选择。线性核不能很好地解决分类任务,rbf核也不是很理想。在右侧,花瓣长和花瓣宽这两个属性被选中作为特征,此时线性核就能很好地进行区分。正确地特征选择,合适的算法,高效地调参是成功地关键。
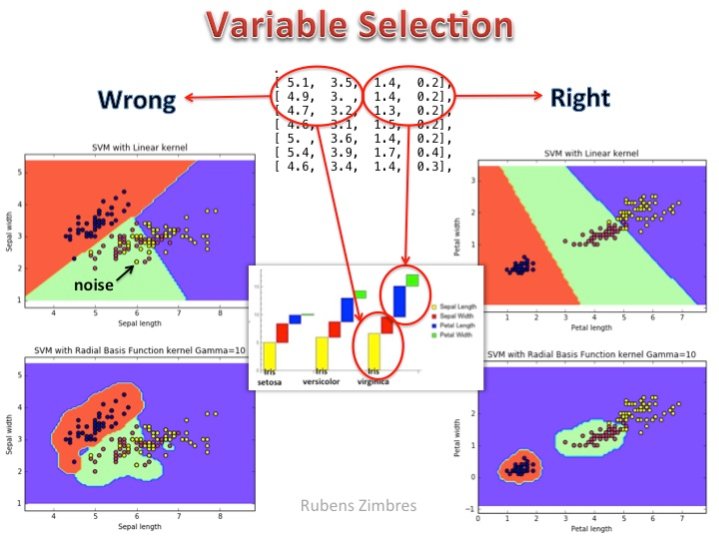
最近以来,大量的数据预处理技术使得我们开始忽视特征选择的意义,但需要记住的是这种情况只适用于特征选择只是用来减少训练时间的应用场合。如Zimbre提到的一个简单而具体的例子,特征选择是区分一个高效的泛化好的模型和一个纯属浪费时间模型的重要标志。
P.S.
推荐两篇神经影像领域应用特征选择算法的论文:
| Date | Title | Authors | Journal |
|---|---|---|---|
| 2013 | A Review of Feature Reduction Techniques in Neuroimaging | Benson Mwangi & Tian Siva Tian & Jair C. Soares | Neuroinform |
| 2016 | Comparison of Feature Selection Techniques in Machine Learning for Anatomical Brain MRI in Dementia | *J Tohka, E Moradi, H Huttunen | Neuroinform |
Comments