2017-08-21
MacLearn
machine-learning
class-imbalanced
In the imbalanced class distribution cases, the classifiers tend to produce high classification accuracies on the majority calss but poor classification accuracies on the minority ones. Class imbalance problem has been studied by many researchers, and the proposed methods can be categorized under three headings:
- Pre-sampling methods
makes the training set balanced, either by oversampling the minority class or by undersampling the majority class.
- Cost-sensitive methods
assigns a higher misclassification cost to the minority class than to the majority class.
- Other methods
integrating sampling with training process.
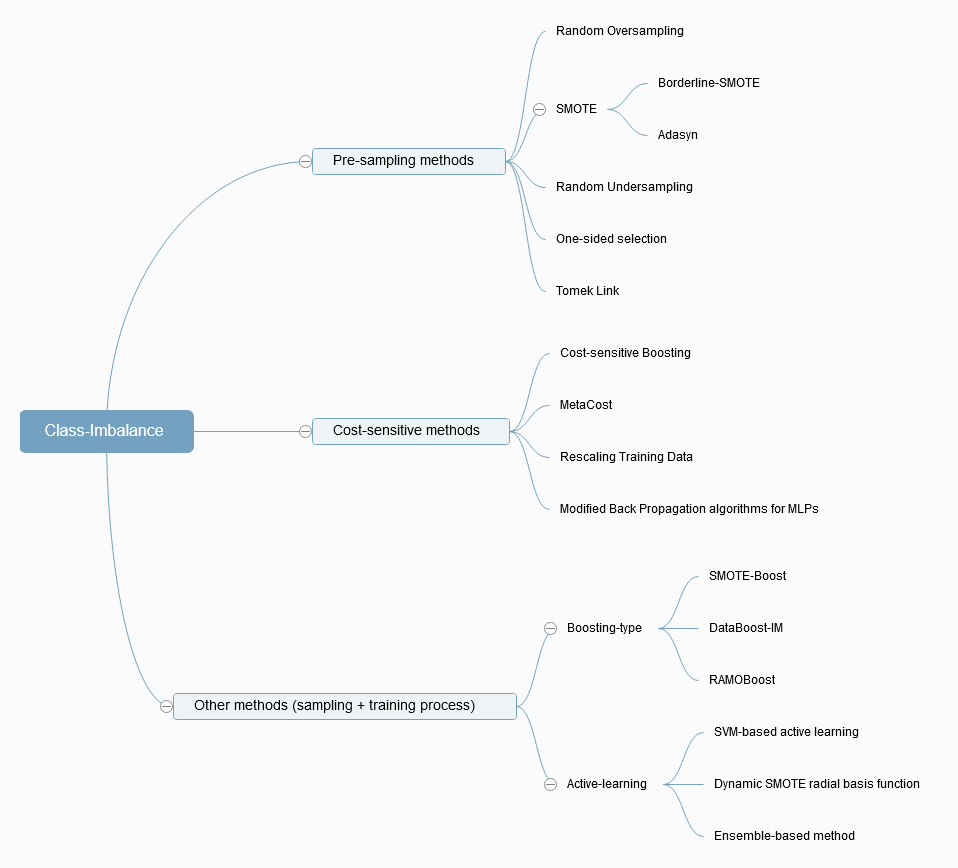 A mindmap that summarizes the methods referred in [2].
A mindmap that summarizes the methods referred in [2].
P.S
A python package offering a number of re-sampling techniques commonly used in datasets showing strong between-class imbalance [3]. imbalanced-learn
Reference
[1] Nitesh Chawla, Kevin Bowyer, Lawrence Hall, W Philip Kegelmeyer. (2002). SMOTE: Synthetic Minority Over-sampling Technique. JMLR
[2] Minlong Lin, Ke Tang, Xin Yao. (2013). Dynamic Sampling Approach to Training Neural Networks for Multiclass Imbalance Classification. IEEE TNNLS
[3] Imbalanced-Learn (A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning)
2017-08-04
MacLearn
machine-learning
A Few Useful Things to Know about Machine Learning
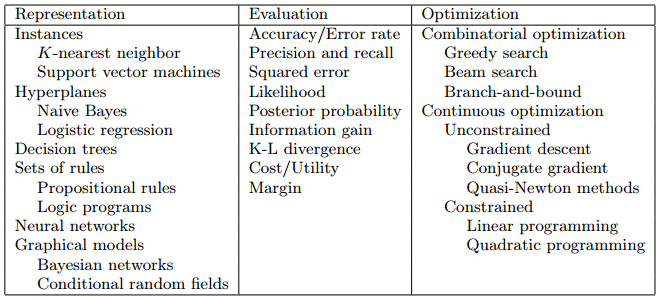
Learning = Representation + Evaluation + Optimization
- Representation
A classifier must be represented in some formal language that the computer can handle. Conversely, choosing a representation for a learner is tantamount to choosing the set of classifiers that it can possibly learn. This set is called the hypothesis space of the learner. If a classifier is not in the hypothesis space, it cannot be learned. A related question, which we will address in a later section, is how to represent the input, i.e., what features to use.
- Evaluation
An evaluation function (also called objective function or scoring function) is needed to distinguish good classifiers from bad ones. The evaluation function used internally by the algorithm may differ from the external one that we want the classifier to optimize, for ease of optimization (see below) and due to the issues discussed in the next section.
- Optimization
Finally, we need a method to search among the classifiers in the language for the highest-scoring one. The choice of optimization technique is key to the efficiency of the learner, and also helps determine the classifier produced if the evaluation function has more than one optimum. It is common for new learners to start out using off-the-shelf optimizers, which are later replaced by custom-designed ones.
与之对应的,在《统计学习方法》的1.3节,也有对统计学习方法三要素的总结:
方法 = 模型(Model) + 策略(Strategy) + 算法(Algorithm)
- 模型
所要学习的条件概率分布或决策函数。
- 策略
模型选择的准则。
- 算法
实现求解最优模型的算法。
Reference
[1] Pedro Domingos (2012). A Few Useful Things to Know about Machine Learning. Communications of the ACM
[2] 李航 (2012). 《统计学习方法》 清华大学出版社
2017-07-16
读书-杂谈
essay
两年研究僧的学习与科研感悟。
关于学习
关于科研
- 方法和问题
- 老方法 + 老问题 (验证/综述)
- 老方法 + 新问题
- 新方法 + 老问题
- 新方法 + 新问题
- 科研过程
定义一个问题,假设结果存在,首先根据现有知识尽可能地缩小结果域,然后使用正确的方法提高搜索的速度,最后靠暴力遍历出结果。当然也有这么干的,即把各种方法都试一遍,根据好的结果重新定义问题,私以为这种为了发文章而做科研的套路是不可取的。
P.S
[1] 百度百科-守破离
[2] The illustrated guide to a Ph.D
[2] 田渊栋-博士五年总结
2017-07-13
MacLearn
machine-learning
feature-selection
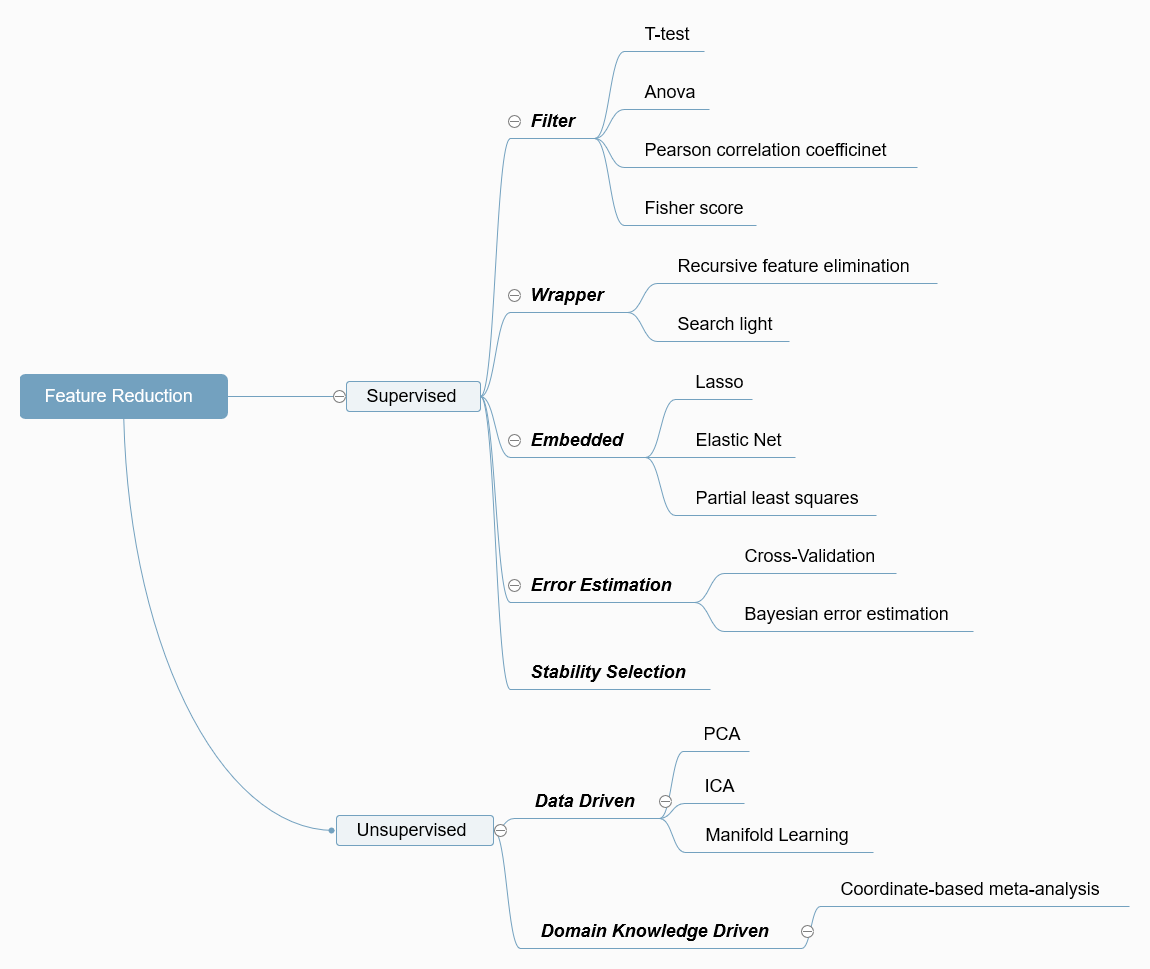
A Mind Map of both Supervised and Unsupervised Feature Reduction Techniques
Retionale for Feature Reduction
- Mitigating the effect of curse-of-dimensionality and the risk of overfitting by preselecting the most relevant features and effectively discarding redundant features plus noise.
- Facilitating a deeper understanding of the scientific question of interest by selecting the features with most contributions to classification or regression.
- Saving the computation time by training the model with a dimension-reduced dataset.
Brief Intro of Feature Reduction (Supervised) Methods
- Filters for feature selection
Filters use simple statistical measures (e.g. mean, variance, correlation coefficients) to rank features according to their relevance in detecting group-level differences.
- Wrappers for feature selection
Wrappers use an objective function from a classification or regression machine learning model to rank features according to their relevance to the model.
- Embedded feature selection
Embedded methods select relevant features as ‘part’ of the machine learning process by enforcing certain ‘penalties’ on a machine learning model thus yielding a small subset of relevant features.
- Parameter selection based on error estimation
Selecting the regularization parameters based on error estimation. The parameter or feature combination giving the highest average accuracy (or AUC, recall-score, f1-score, etc.) is selected. Except for the non-parametric error estimation techniques (such as CV or bootstrap), the recently proposed alternative - “The Parametric Bayesian error estimator” can be applied to feature selection [1].
- Stability selection
Stability selection is a recently proposed approach by Meinshausen and Buhlmann [2] for addressing the problem of selecting the proper amount of regularization in embedded FS algorithms. This approach is based on subsampling combined with the FS algorithm. The key idea of this method is that, instead of finding the best value of the regularization and using it, one applies a FS method many times to random subsamples of the data for different value of the regularization parameters and selects those variables that were most frequently selected on the resulting subsamples.
Brief Intro of Feature Reduction (Unsupervised) Methods
- PCA
PCA is used to decompose a multivariate dataset in a set of successive orthogonal components that explain a maximum amount of the variance.
- ICA
Independent component analysis separates a multivariate signal into additive subcomponents that are maximally independent.
- Manifold Learning
Manifold learning is an approach to non-linear dimensionality reduction. Algorithms for this task are based on the idea that the dimensionality of many data sets is only artificially high.
- Domain Knowledge Driven
Domain knowledge is valid knowledge used to refer to an area of human endeavour, an autonomous computer activity, or other specialized discipline. [3-4]
More about Dimension Reduction - [8]
Feature selection techniques in Scikit-Learn (0.17.1) [link]
- Filters
- Wrappers for feature selection
- Embedded feature selection
- Stability selection
Dimension Reduction techniques in Scikit-Learn (0.18.2) [Link]
Reference
[1] Dalton, L.A., & Dougherty, E.R. (2011). Bayesian minimum meansquare error estimation for classification error—part II: The Bayesian MMSE error estimator for linear classification of Gaussian distributions. IEEE Trans Signal Process
[2] Meinshausen and Buhlmann. (2010). Stability selection. Journal of the Royal Statistical Society: Series B (Statistical Methodology)
[3] Domain knowledge | Wikipedia
[4] Domain driven data mining | Wikipedia
[5] L. Breiman, and A. Cutler. Random Forests. [Home]
[6] Benson Mwangi & Tian Siva Tian & Jair C. Soares. (2013). A Review of Feature Reduction Techniques in Neuroimaging. Neuroinform
[7] J Tohka, E Moradi, H Huttunen. (2016). Comparison of Feature Selection Techniques in Machine Learning for Anatomical Brain MRI in Dementia. Neuroinform
[8] L.J.P. van der Maaten, E.O. Postma, H.J. van den Herik. (2008). Dimensionality Reduction: A Comparative Review Preprint












